详解IBM SPSS Statistics两步聚类之参数设置
SPSS的快速聚类(K均值聚类)仅可进行连续型变量的聚类;而系统聚类,虽然可进行连续型与分类型变量的聚类,但同一时间只能进行同一种变量类型的聚类分析。那么,有没有一种聚类方法可同时分析以上两种变量?
答案是肯定的,IBM SPSS Statistics的两步聚类,也称为二阶聚类,就可以同时进行以上两种变量的聚类分析。不仅如此,两步聚类还能分析各种变量的聚类重要性。接下来,我们通过实例来详细了解下吧。
一、数据准备
本例使用的是一组包含客流量、销售额、销售量三个连续型变量,以及店铺类型、星级、所处区域三个分类变量的数据。
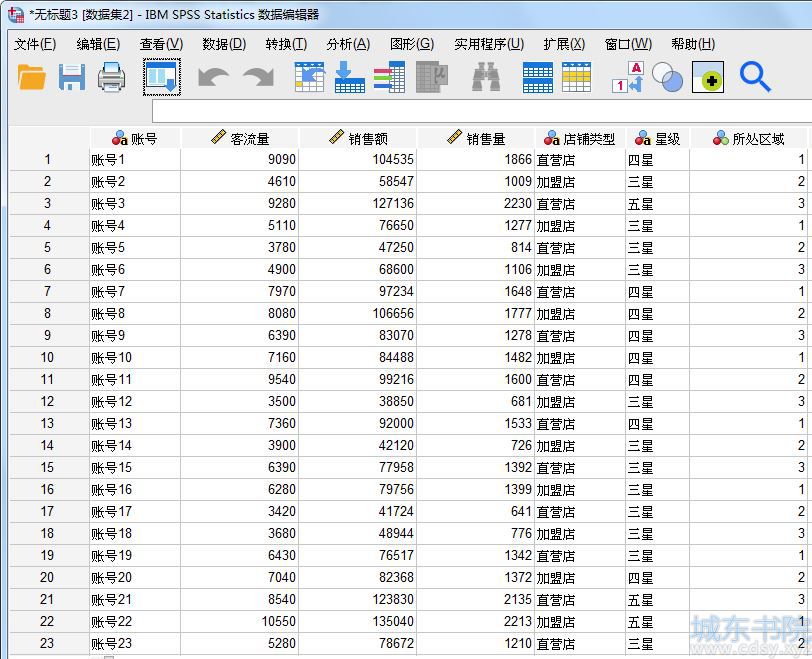
图1:店铺数据
二、二阶聚类参数设置
如图1所示,依次单击分析-分类-二阶聚类选项。
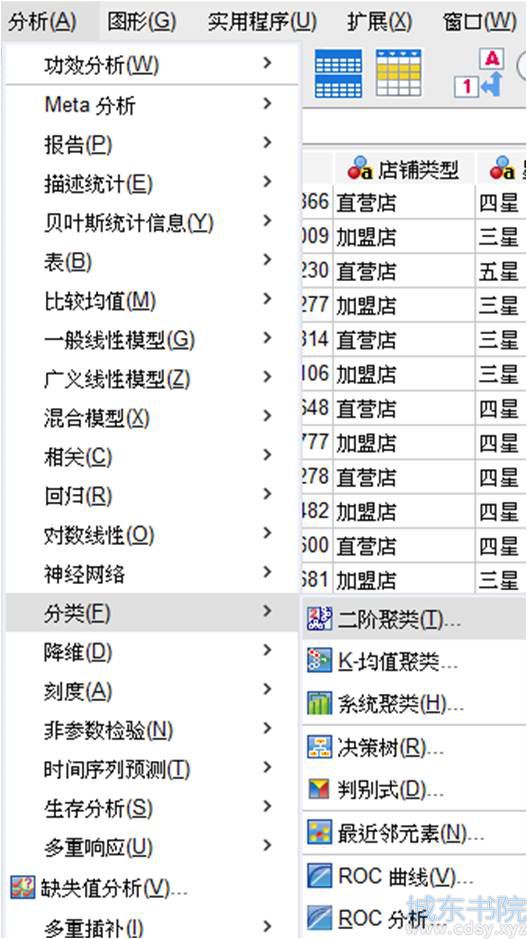
图2:二阶聚类
两步聚类,在SPSS也称为二阶聚类,是通过两个步骤来完成聚类分析。
第一步,通过指定的距离测量(如对数似然或欧式距离)构建分类树,将距离相近的记录为一个树节点;第二步,在分类树基础上,确定聚类分类,并通过BIC或AIC准则判断,以确定聚类结果。
根据以上原理,我们需要进行变量、距离测量、聚类准则等参数设置。
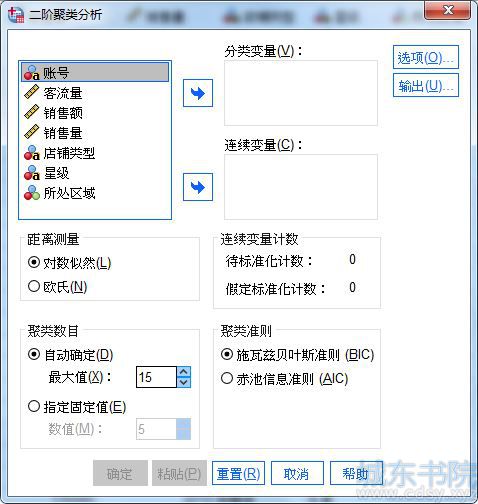
图3:参数设置面板
首先,将店铺类型、星级、所处区域设置为分类变量;将客流量、销售额、销售量设置为连续变量。
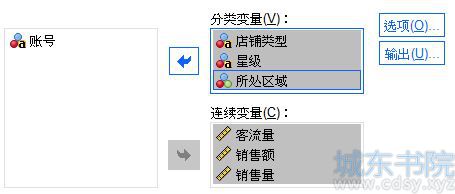
图4:变量设置
接着,在距离测量中,设置对数似然法,因欧式距离测量只能用于分析的所有变量都是连续变量的情况。
在聚类数目中,设置自动确定,并保持默认的最大值为15。
在聚类准则中,以BIC作为聚类的判断准则。

图5:计算方法
在选项设置中,保持默认的最大内存分配64MB,以及默认的待标准化计数变量,以统一变量的测量尺度。
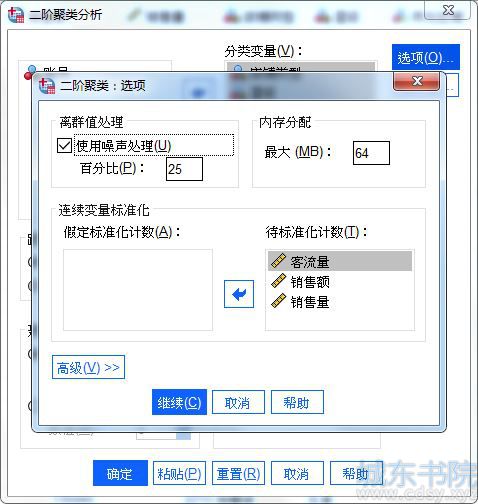
图6:选项设置
最后,在输出设置中,勾选“透视表”,即得到聚类的结果输出;勾选“图表和表(在模型查看器中)”,可进一步查看变量贡献的重要性,以及可视化数据;勾选“创建聚类成员变量”,以了解个案对应的类。
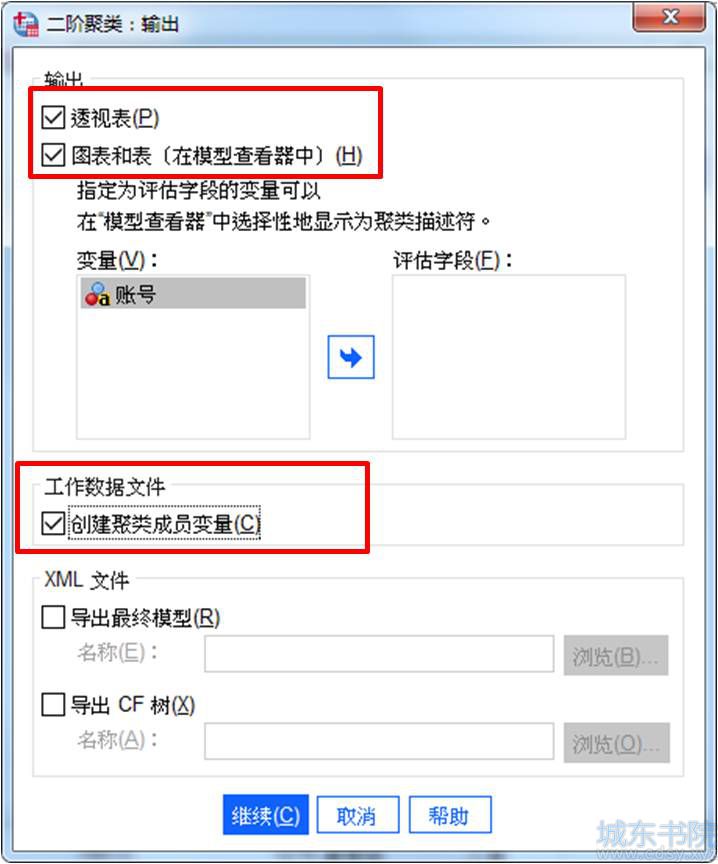
图7:输出设置
三、小结
综上所述,相比于K均值聚类、系统聚类,两步聚类可用于分析的变量类型更广,并且可将所有变量类型放在一起进行大样本的数据运算。
关于两步聚类的结果解读,可在城东书院网站查阅《详解SPSS两步聚类之结果解读》一文。








 湘公网安备 43102202000103号
湘公网安备 43102202000103号