python学习之struct模块
class struct.Struct(format)
返回一个struct对象(结构体,参考C)。
该对象可以根据格式化字符串的格式来读写二进制数据。
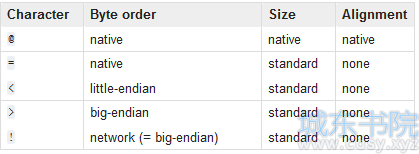
第一个参数(格式化字符串)可以指定字节的顺序。
默认是根据系统来确定,也提供自定义的方式,只需要在前面加上特定字符即可:
struct.Struct('>I4sf')
特定字符对照表附件有。
常见方法和属性:
方法
pack
(v1, v2, …)
返回一个字节流对象。
按照fmt(格式化字符串)的格式来打包参数v1,v2,...。
通俗的说就是:
首先将不同类型的数据对象放在一个“组”中(比如元组(1,'good',1.22)),
然后打包(“组”转换为字节流对象),最后再解包(将字节流对象转换为“组”)。
pack_into(buffer, offset, v1, v2, …)
根据格式字符串fmt包装值v1,v2,...,并将打包的字节写入从位置偏移开始的可写缓冲buffer。请注意,offset是必需的参数。
unpack_from(buffer, offset=0)
根据格式字符串fmt,从位置偏移开始从缓冲区解包。 结果是一个元组,即使它只包含一个项目。缓冲区的大小(以字节为单位,减去偏移量)必须至少为格式所需的大小,如calcsize()所反映的。
属性
format
格式化字符串。
size
结构体的大小。
实例:
1.通常的打包和解包
# -*- coding: utf-8 -*-
"""
打包和解包
"""
import struct
import binascii
values = (1, b'good', 1.22) #查看格式化对照表可知,字符串必须为字节流类型。
s = struct.Struct('I4sf')
packed_data = s.pack(*values)
unpacked_data = s.unpack(packed_data)
print('Original values:', values)
print('Format string :', s.format)
print('Uses :', s.size, 'bytes')
print('Packed Value :', binascii.hexlify(packed_data))
print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data)
结果:
Original values: (1, b'good', 1.22)
Format string : b'I4sf'
Uses : 12 bytes
Packed Value : b'01000000676f6f64f6289c3f'
Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295)
[Finished in 0.1s]
说明:
首先将数据对象放在了一个元组中,然后创建一个Struct对象,并使用pack()方法打包该元组;最后解包返回该元组。
这里使用到了binascii.hexlify(data)函数。
binascii.hexlify(data)
返回字节流的十六进制字节流。
>>> a = 'hello'
>>> b = a.encode()
>>> b
b'hello'
>>> c = binascii.hexlify(b)
>>> c
b'68656c6c6f'
2.使用buffer来进行打包和解包
使用通常的方式来打包和解包会造成内存的浪费,所以python提供了buffer的方式:
# -*- coding: utf-8 -*-
"""
通过buffer方式打包和解包
"""
import struct
import binascii
import ctypes
values = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。
s = struct.Struct('I4sf')
buff = ctypes.create_string_buffer(s.size)
packed_data = s.pack_into(buff,0,*values)
unpacked_data = s.unpack_from(buff,0)
print('Original values:', values)
print('Format string :', s.format)
print('buff :', buff)
print('Packed Value :', binascii.hexlify(buff))
print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data)
结果:
Original values1: (1, b'good', 1.22)
Original values2: (b'hello', True)
buff : <ctypes.c_char_Array_18 object at 0x000000D5A5617348>
Packed Value : b'01000000676f6f64f6289c3f68656c6c6f01'
Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295)
Unpacked Type : <class 'tuple'> Value: (b'hello', True)
[Finished in 0.1s]
说明:
针对buff对象进行打包和解包,避免了内存的浪费。
这里使用到了函数
ctypes.create_string_buffer(init_or_size,size = None)
创建可变字符缓冲区。
返回的对象是c_char的ctypes数组。
init_or_size必须是一个整数,它指定数组的大小,或者用于初始化数组项的字节对象。
3.使用buffer方式来打包多个对象
# -*- coding: utf-8 -*-
"""
buffer方式打包和解包多个对象
"""
import struct
import binascii
import ctypes
values1 = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。
values2 = (b'hello',True)
s1 = struct.Struct('I4sf')
s2 = struct.Struct('5s?')
buff = ctypes.create_string_buffer(s1.size+s2.size)
packed_data_s1 = s1.pack_into(buff,0,*values1)
packed_data_s2 = s2.pack_into(buff,s1.size,*values2)
unpacked_data_s1 = s1.unpack_from(buff,0)
unpacked_data_s2 = s2.unpack_from(buff,s1.size)
print('Original values1:', values1)
print('Original values2:', values2)
print('buff :', buff)
print('Packed Value :', binascii.hexlify(buff))
print('Unpacked Type :', type(unpacked_data_s1), ' Value:', unpacked_data_s1)
print('Unpacked Type :', type(unpacked_data_s2), ' Value:', unpacked_data_s2)
结果:
Original values2: (b'hello', True)
buff : <ctypes.c_char_Array_18 object at 0x000000D5A5617348>
Packed Value : b'01000000676f6f64f6289c3f68656c6c6f01'
Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295)
Unpacked Type : <class 'tuple'> Value: (b'hello', True)
[Finished in 0.1s]
附:
1.格式化对照表

提示:
signed char(有符号位)取值范围是 -128 到 127(有符号位)
unsigned char (无符号位)取值范围是 0 到 255
2.字节顺序,大小和校准








 湘公网安备 43102202000103号
湘公网安备 43102202000103号