爬取安居客租房详情+翻页
时间:03-29来源:作者:点击数:
爬取链接:https://wf.zu.anjuke.com/?from=navigation
首先我们先打开浏览器,输入网址,利用network进行抓包,找到type ducument响应源码文件
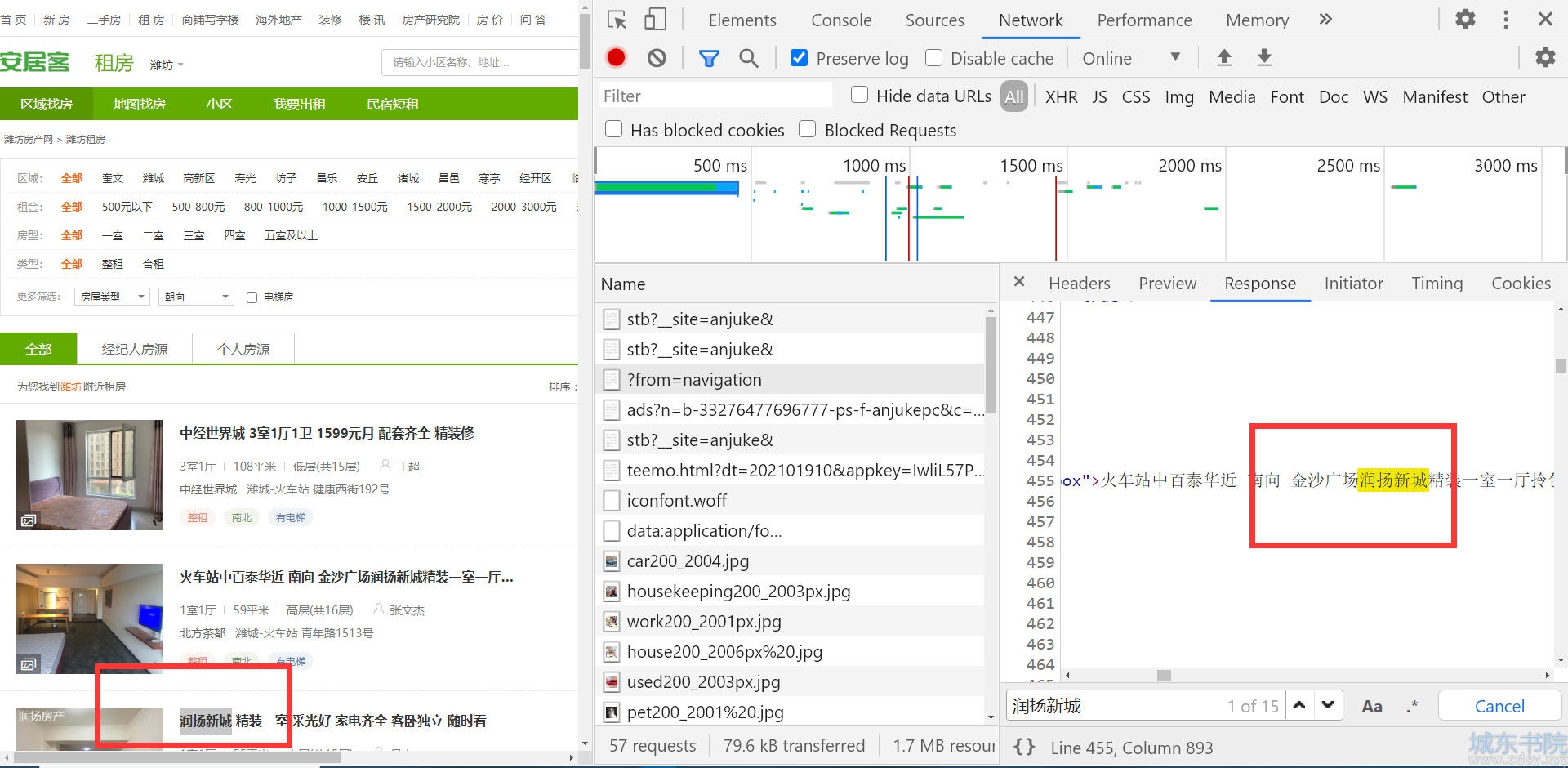
我们发现我们要爬取的数据在html源码中,那么我们就方便了,使用requests和lxml配合使用爬取租房信息,采用面向对象进行开发,方便代码修改,然后我们编写代码!!!
# -- coding: utf-8 --
# @Time : 2020/12/28 15:40
# @FileName: Anjuke.py
# @Software: PyCharm
import requests
from lxml import etree
import csv
from pymongo import MongoClient
class Anjuke(object):
def __init__(self):
self.url = 'https://wf.zu.anjuke.com/?from=navigation'
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 ',
'referer': 'https://weifang.anjuke.com/'
}
self.client = MongoClient("127.0.0.1", 27017)
self.db = self.client['Anjuke']
self.col = self.db['House']
def get_data(self):
proxies_url = 'http://webapi.http.zhimacangku.com/getip?num=20&type=2&pro=&city=0&yys=0&port=1&pack=131877&ts' \
'=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=1®ions= '
res = requests.get(proxies_url)
dict_data = json.loads(res.content)
for agent in dict_data["data"]:
ip = agent['ip']
port = agent['port']
# 代理服务器
proxyHost = ip
proxyPort = port
proxyMeta = "http://%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
}
self.proxies = {
"http": proxyMeta
}
response = requests.get(url=self.url, proxies=self.proxies)
return response
def parse_data(self, response):
html = etree.HTML(response.content)
node_list = html.xpath('//div[@class="zu-itemmod"]')
data_list = list()
for node in node_list:
temp = {}
temp["标题"] = node.xpath("./div[1]/h3/a/b/text()")[0]
temp["链接"] = node.xpath("./div[1]/h3/a/@href")[0]
temp["价格"] = node.xpath("./div[2]/p/strong/b/text()")[0] + '元'
temp["大小"] = node.xpath("./div[1]/p[1]/b[3]/text()")[0] + '平米'
shi = node.xpath("./div[1]/p[1]/b[1]/text()")[0]
ting = node.xpath("./div[1]/p[1]/b[2]/text()")[0]
temp["户型"] = shi + '室' + ting + '厅'
temp["姓名"] = node.xpath("./div[1]/p[1]/text()[6]")[0].strip()
temp["小区"] = node.xpath("./div[1]/address/a/text()")[0]
temp["地址"] = node.xpath("./div[1]/address/text()")[1].strip()
temp["整租"] = node.xpath("./div[1]/p[2]/span[1]/text()")[0]
temp["方向"] = node.xpath("./div[1]/p[2]/span[2]/text()")[0]
detail_link = temp["链接"]
self.url = detail_link
print(self.url)
response = requests.get(url=self.url, headers=self.headers)
html = etree.HTML(response.content)
try:
temp["要求"] = html.xpath('/html/body/div[3]/div[2]/div[1]/ul[1]/li[1]/span[2]/text()')[0]
except:
temp["要求"] = "空"
try:
temp["描述"] = html.xpath('/html/body/div[3]/div[2]/div[1]/div[6]/b/text()')[0]
except:
temp["描述"] = "空"
try:
temp["图片"] = html.xpath('//*[@id="room_pic_wrap"]/div/img/@data-src')[0]
except:
temp["图片"] = "空"
try:
temp["日期"] = html.xpath('/html/body/div[3]/div[2]/div[1]/div[2]/div/b/text()')[0]
except:
temp["日期"] = "空"
print(temp)
data_list.append(temp)
return data_list
def save_data(self, data_list):
for data in data_list:
csv_writer.writerow(
[data["标题"], data["链接"], data["价格"], data["大小"], data["户型"], data["姓名"], data["小区"], data["地址"],
data["整租"], data["方向"], data["要求"], data["描述"], data["图片"], data["日期"]])
self.col.insert_one(data)
self.client.close()
def run(self):
while True:
response = self.get_data()
data_list = self.parse_data(response)
self.save_data(data_list)
html = etree.HTML(response.content)
try:
next_url = html.xpath('//*[contains(text(),"下一页")]/@href')[0]
print(next_url)
self.url = next_url
except:
break
if __name__ == '__main__':
head = ["标题", "链接", "价格", "大小", "户型", "姓名", "小区", "地址", "整租", "方向", "要求", "描述", "图片", "日期"]
with open('安居客.csv', 'w', newline='', encoding="gb18030") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(head)
anjuke = Anjuke()
anjuke.run()
将数据存储到csv中,并存储到mongodb数据库,并且实现了翻页功能,其中还添加了代理,因为在打开详情页时访问频繁被屏蔽403,利用代理ip进行爬取!
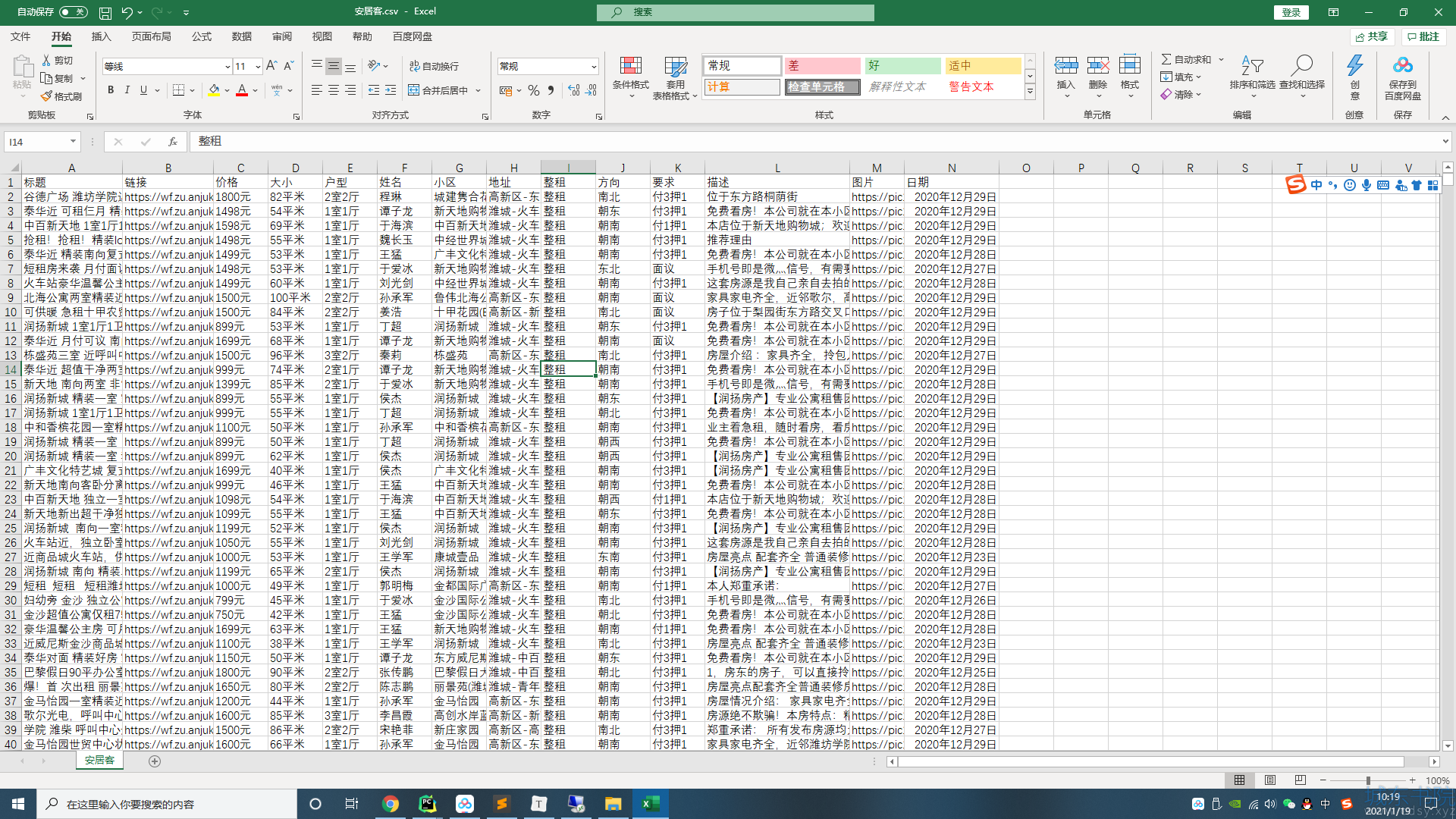

我爬取的是潍坊,如果想爬其他的地方,wf换成你想爬的城市的缩写就行
希望大家多多给我点赞呀!

方便获取更多学习、工作、生活信息请关注本站微信公众号


上一篇:爬虫基础
下一篇:scrapy抓取贝壳找房租房数据





 湘公网安备 43102202000103号
湘公网安备 43102202000103号